
一、RAG 技术及其局限
检索增强生成(RAG)技术是连接外部数据源以提升大型语言模型输出效果的重要手段。它能让 LLMs 访问私有或特定领域数据,有效缓解幻觉问题,在 AI 聊天机器人、推荐系统等 GenAI 应用中广泛应用。
通常,基础的 RAG 会整合向量数据库和 LLMs。向量数据库负责存储和检索用户查询的上下文信息,LLMs 则依据检索到的内容生成答案。然而,在面对多跳推理或需要整合不同信息片段的复杂问题时,基础 RAG 就显得力不从心了。
二、GraphRAG 闪亮登场
为应对这些挑战,微软研究院推出了 GraphRAG。与仅使用向量数据库检索语义相似文本的基础 RAG 不同,GraphRAG 创新性地融入了知识图谱(KGs)。知识图谱是一种基于数据间关系存储和链接相关或不相关数据的数据结构。
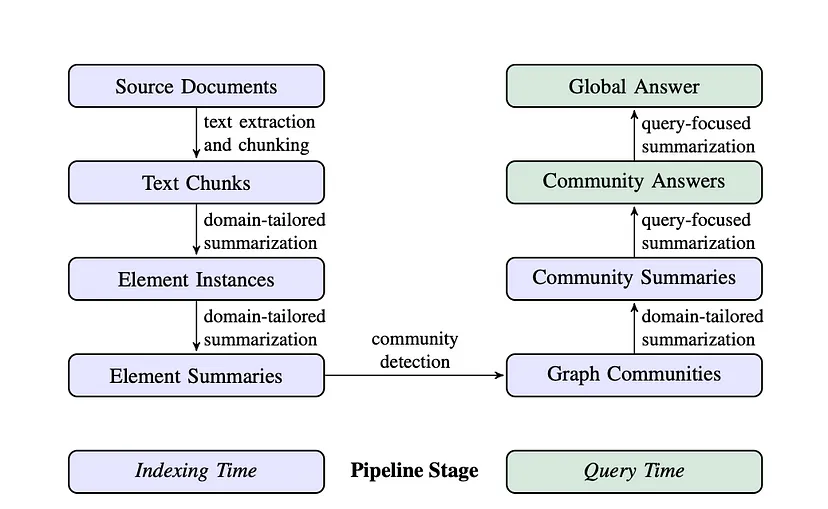
(一)GraphRAG 工作流程之索引阶段
- 文本单元分割:将整个输入语料库分割成多个文本单元(如段落、句子等逻辑单元)。这样做就像把大蛋糕切成小块,能让我们更精细地提取和保存输入数据的详细信息。例如,对于一篇关于历史事件的长文档,分割后可以针对每个小段的信息进行深入分析,而不是在整体上进行笼统处理。
- 实体、关系和声明提取:利用 LLMs 从每个文本单元中识别并提取出所有实体(如人物、地点、组织等名称)、它们之间的关系以及文本中表达的关键声明。这些提取出的信息就像是拼图的碎片,后续会用来构建初始知识图谱。以一部小说为例,会提取出主角、故事发生地、人物之间的情感关系等信息。

- 层次聚类:采用 Leiden 技术对初始知识图谱进行层次聚类。Leiden 算法就像一个敏锐的侦探,能够有效发现图中的社区结构。每个社区内的实体紧密相连,而不同社区之间的连接相对稀疏。通过这种方式,可以对数据进行更有针对性的分析。比如在一个包含多个学科知识的图谱中,数学相关的知识可能会聚类成一个社区,物理相关的形成另一个社区。
- 社区总结生成:使用自下而上的方法为每个社区及其成员生成总结。总结涵盖社区内的主要实体、它们的关系和关键声明,为后续查询提供了数据集的整体概览和有用的上下文信息。这就好比给每个社区制作了一张名片,让我们能快速了解其核心内容。
(二)GraphRAG 工作流程之查询阶段
GraphRAG 针对不同类型的查询设计了两种工作流程:
-
全局搜索:适用于与整个数据集相关的整体性问题推理。它借助社区总结来进行,就像从地图的全景视角出发寻找答案。具体步骤如下:
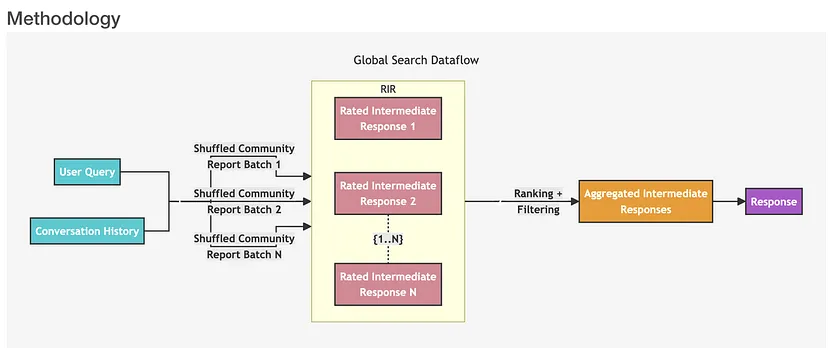
- 首先,系统以用户查询和对话历史作为初始输入,这就像是给搜索任务提供了一个起点和背景信息。
- 然后,使用由 LLMs 从社区层次结构的指定级别生成的节点社区报告作为上下文数据,并将这些报告打乱分成多个批次。
- 接着,将每个批次的社区报告进一步分割成预定义大小的文本块,每个文本块用于生成包含信息点列表的中间响应,每个信息点都有一个表示其重要性的数值分数。
- 之后,对这些中间响应进行排序和筛选,选出最重要的信息点,形成聚合中间响应。
- 最后,以聚合中间响应为上下文生成最终回复。
-
局部搜索:用于对特定实体进行推理。当用户询问关于特定实体(如人物、地点、组织等)的问题时,推荐使用此流程。它就像聚焦在一个具体的地点进行深入探索,步骤如下:
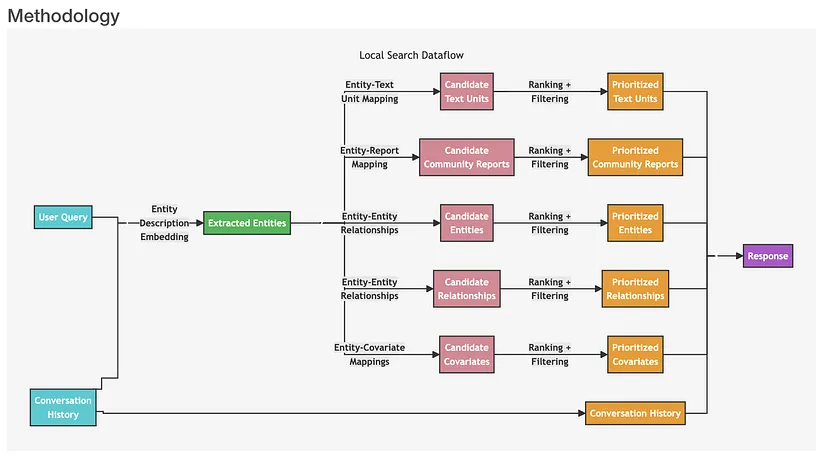
- 系统接收用户查询后,先从知识图谱中识别出一组与用户输入语义相关的实体,这一步利用 Milvus 等向量数据库进行文本相似性搜索,找到的这些实体就像是进入知识图谱的入口。
- 接着将提取的文本单元映射到相应实体,并去除原始文本信息,使数据更加精炼。
- 然后提取实体及其对应关系的特定信息,进一步明确实体之间的联系。
- 再将实体映射到其协变量(可能包括统计数据或其他相关属性),丰富实体的描述。
- 之后将社区报告整合到搜索结果中,引入一些全局信息,拓宽视野。
- 如果有对话历史,系统会利用它更好地理解用户意图和上下文,使回答更贴合用户需求。
- 最后,基于前面步骤生成的经过筛选和排序的数据构建并回答用户查询。
三、GraphRAG 与基础 RAG 的输出质量对比
为展示 GraphRAG 的有效性,其研发团队在实验中使用了包含敏感话题的 Violent Incident Information from News Articles (VIINA) 数据集。在回答“数据集中的前 5 个主题是什么?”这一问题时,基础 RAG 由于向量搜索检索到不相关文本,结果与战争主题无关,导致评估不准确。而 GraphRAG 则能提供清晰且相关的答案,准确识别出主要主题和支持细节,答案与数据集高度契合,并能引用源材料。进一步的实验表明,GraphRAG 在多跳推理和复杂信息总结方面表现卓越,在全面性和多样性上均超越了基础 RAG。全面性体现在答案对问题各个方面的覆盖程度,多样性则表现在答案所提供的视角和见解的丰富多样。
四、GraphRAG 与 Milvus 向量数据库的结合实现
GraphRAG 借助知识图谱增强 RAG 应用的同时,也依赖向量数据库来检索相关实体。下面我们以使用 Milvus 向量数据库为例,介绍 GraphRAG 的实现过程。
(一)准备工作
在运行代码前,需要安装以下依赖:
pip install --upgrade pymilvus
pip install git+https://github.com/zc277584121/graphrag.git
这里安装 GraphRAG 时使用了一个 fork 仓库,原因是在撰写本文时 Milvus 存储功能尚未正式合并。
(二)数据准备与索引创建
- 从 Project Gutenberg 下载一个约一千行的小型文本文件(这里以达芬奇的故事为例),用于 GraphRAG 索引。
import nest_asyncio
nest_asyncio.apply()
import os
import urllib.request
index_root = os.path.join(os.getcwd(), 'graphrag_index')
os.makedirs(os.path.join(index_root, 'input'), exist_ok=True)
url = "https://www.gutenberg.org/cache/epub/7785/pg7785.txt"
file_path = os.path.join(index_root, 'input', 'davinci.txt')
urllib.request.urlretrieve(url, file_path)
with open(file_path, 'r+', encoding='utf-8') as file:
lines = file.readlines()
file.seek(0)
file.writelines(lines[:934]) # 可根据需要调整此数字以节省 API 密钥成本
file.truncate()
- 初始化工作区:
python -m graphrag.index --init --root./graphrag_index
- 配置环境文件和设置:在索引根目录下找到.env 文件,添加 OpenAI API 密钥。需要注意的是,本示例使用 OpenAI 模型,务必提前准备好 API 密钥。同时,GraphRAG 索引过程因需用 LLMs 处理整个文本语料库,成本较高,可考虑截断文本文件以节省费用。
- 运行索引管道:
python -m graphrag.index --root./graphrag_index
索引完成后,会在 ./graphrag_index/output/<timestamp>/artifacts 目录下生成一系列 parquet 文件。
(三)使用 Milvus 向量数据库进行查询
- 加载索引过程中生成的数据,并将实体描述信息存储到 Milvus 向量数据库中:
import os
import pandas as pd
import tiktoken
from graphrag.query.context_builder.entity_extraction import EntityVectorStoreKey
from graphrag.query.indexer_adapters import (
# read_indexer_covariates,
read_indexer_entities,
read_indexer_relationships,
read_indexer_reports,
read_indexer_text_units,
)
from graphrag.query.input.loaders.dfs import (
store_entity_semantic_embeddings,
)
from graphrag.query.llm.oai.chat_openai import ChatOpenAI
from graphrag.query.llm.oai.embedding import OpenAIEmbedding
from graphrag.query.llm.oai.typing import OpenaiApiType
from graphrag.query.question_gen.local_gen import LocalQuestionGen
from graphrag.query.structured_search.local_search.mixed_context import (
LocalSearchMixedContext,
)
from graphrag.query.structured_search.local_search.search import LocalSearch
from graphrag.vector_stores import MilvusVectorStore
output_dir = os.path.join(index_root, "output")
subdirs = [os.path.join(output_dir, d) for d in os.listdir(output_dir)]
latest_subdir = max(subdirs, key=os.path.getmtime) # 获取最新输出目录
INPUT_DIR = os.path.join(latest_subdir, "artifacts")
COMMUNITY_REPORT_TABLE = "create_final_community_reports"
ENTITY_TABLE = "create_final_nodes"
ENTITY_EMBEDDING_TABLE = "create_final_entities"
RELATIONSHIP_TABLE = "create_final_relationships"
COVARIATE_TABLE = "create_final_covariates"
TEXT_UNIT_TABLE = "create_final_text_units"
COMMUNITY_LEVEL = 2
# 读取实体
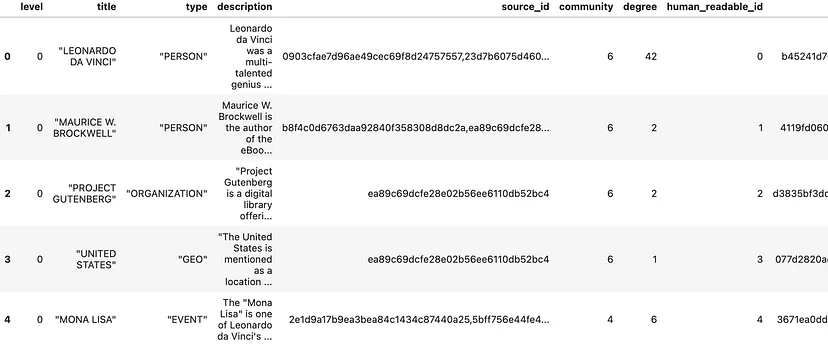
entity_df = pd.read_parquet(f"{INPUT_DIR}/{ENTITY_TABLE}.parquet")
entity_embedding_df = pd.read_parquet(f"{INPUT_DIR}/{ENTITY_EMBEDDING_TABLE}.parquet")
entities = read_indexer_entities(entity_df, entity_embedding_df, COMMUNITY_LEVEL)
description_embedding_store = MilvusVectorStore(
collection_name="entity_description_embeddings",
# description_embedding_store.connect(uri="http://localhost:19530") # 用于 Milvus docker 服务
description_embedding_store.connect(uri="./milvus.db") # 用于 Milvus Lite
)
entity_description_embeddings = store_entity_semantic_embeddings(
entities=entities, vectorstore=description_embedding_store
)
print(f"Entity count: {len(entity_df)}")
entity_df.head()
# 读取关系
relationship_df = pd.read_parquet(f"{INPUT_DIR}/{RELATIONSHIP_TABLE}.parquet")
relationships = read_indexer_relationships(relationship_df)
print(f"Relationship count: {len(relationship_df)}")
relationship_df.head()
# 读取社区报告
report_df = pd.read_parquet(f"{INPUT_DIR}/{COMMUNITY_REPORT_TABLE}.parquet")
reports = read_indexer_reports(report_df, entity_df, COMMUNITY_LEVEL)
print(f"Report records: {len(report_df)}")
report_df.head()
# 读取文本单元
text_unit_df = pd.read_parquet(f"{INPUT_DIR}/{TEXT_UNIT_TABLE}.parquet")
text_units = read_indexer_text_units(text_unit_df)
print(f"Text unit records: {len(text_unit_df)}")
text_unit_df.head()
- 创建本地搜索引擎:
api_key = os.environ["OPENAI_API_KEY"]
llm_model = "gpt-4o"
embedding_model = "text-embedding-3-small"
llm = ChatOpenAI(
api_key=api_key,
model=llm_model,
api_type=OpenaiApiType.OpenAI,
max_retries=20,
)
token_encoder = tiktoken.get_encoding("cl100k_base")
text_embedder = OpenAIEmbedding(
api_key=api_key,
api_base=None,
api_type=OpenaiApiType.OpenAI,
model=embedding_model,
deployment_name=embedding_model,
max_retries=20,
)
context_builder = LocalSearchMixedContext(
community_reports=reports,
text_units=text_units,
entities=entities,
relationships=relationships,
covariates=None,
entity_text_embeddings=description_embedding_store,
embedding_vectorstore_key=EntityVectorStoreKey.ID,
text_embedder=text_embedder,
token_encoder=token_encoder,
)
local_context_params = {
"text_unit_prop": 0.5,
"community_prop": 0.1,
"conversation_history_max_turns": 5,
"conversation_history_user_turns_only": True,
"top_k_mapped_entities": 10,
"top_k_relationships": 10,
"include_entity_rank": True,
"include_relationship_weight": True,
"include_community_rank": False,
"return_candidate_context": False,
"embedding_vectorstore_key": EntityVectorStoreKey.ID,
"max_tokens": 12_000,
}
llm_params = {
"max_tokens": 2_000, # 可根据模型的令牌限制进行调整
"temperature": 0.0,
}
search_engine = LocalSearch(
llm=llm,
context_builder=context_builder,
token_encoder=token_encoder,
llm_params=llm_params,
context_builder_params=local_context_params,
response_type="multiple paragraphs"
)
- 进行查询:
result = await search_engine.asearch("Tell me about Leonardo Da Vinci")
print(result.response)
查询结果会详细地介绍达芬奇的相关信息,并且 GraphRAG 的结果会明确标注引用的数据来源,具有较高的可信度和准确性。
此外,GraphRAG 还具备根据历史查询生成问题的功能,这在聊天机器人对话中创建推荐问题时非常实用。它结合知识图谱的结构化数据和输入文档的非结构化数据,生成与特定实体相关的候选问题。
question_generator = LocalQuestionGen(
llm=llm,
context_builder=context_builder,
token_encoder=token_encoder,
llm_params=llm_params,
context_builder_params=local_context_params,
question_history=[
"Tell me about Leonardo Da Vinci",
"Leonardo's early works",
]
)
candidate_questions = await question_generator.agenerate(
question_history=question_history, context_data=None, question_count=5
)
print(candidate_questions.response)
五、总结与展望
在本文中,我们深入探索了 GraphRAG 这一创新技术。它通过整合知识图谱有效增强了 RAG 技术,在处理多跳推理和回答需要链接不同信息的复杂问题方面表现出色。与 Milvus 向量数据库结合后,GraphRAG 能够在大型数据集中驾驭复杂的语义关系,为各种实际的 GenAI 应用提供更准确、更有洞察力的结果,成为理解和处理复杂信息的强大工具。
对于开发者和研究人员来说,GraphRAG 为提升人工智能应用的性能开辟了新的途径。未来,随着技术的不断发展,我们期待 GraphRAG 在更多领域得到应用和完善,进一步推动人工智能技术的进步。
如果您想了解更多关于 GraphRAG 的信息,可以查阅以下资源:
- GraphRAG 论文:《From Local to Global: A Graph RAG Approach to Query-Focused Summarization》
- GraphRAG GitHub 仓库
- 其他 RAG 增强技术相关资料,如
- 《Better RAG with HyDE — Hypothetical Document Embeddings》
- 《Enhancing RAG with Knowledge Graphs using WhyHow》
- 《How to Enhance the Performance of Your RAG Pipeline》
- 《Optimizing RAG with Rerankers: The Role and Trade-offs》《Practical Tips and Tricks for Developers Building RAG Applications》
- 《Infrastructure Challenges in Scaling RAG with Custom AI Models》
希望这篇文章能帮助您更好地理解 GraphRAG 技术,如果您在阅读过程中有任何疑问或建议,欢迎随时与我们交流!欢迎关注公众号 柏企阅文
以上就是今天为您带来的关于 GraphRAG 的深度解析,感谢您的关注!
评论