
深入研究 “NoProp” 算法,无需前向传递和反向传播来训练神经网络,并从头开始学习编码。
论文
NoProp: Training Neural Networks without Back-propagation or Forward-propagation
您不再需要反向传播来训练神经网络
反向传播,于 1986 年首次引入,是我们今天使用的所有流行机器学习模型训练的关键算法之一。它简单易行,在训练大型神经网络中效果显著。
尽管被广泛接受为最好的方法,但它也有一些缺点,包括训练期间内存使用率高以及由于算法的顺序性质而难以并行化训练。
有没有一种算法仍然可以有效地训练神经网络,并且没有这些缺点?
牛津大学的一组研究人员刚刚引入了一种消除反向传播需要的方法。
他们的算法,称为 “NoProp”,甚至不需要前向传递,并且遵循扩散模型遵循的原则,独立训练神经网络的每一层,而无需传递梯度。
这里有一个故事,我们深入研究这个算法是如何工作的,了解它的比较性能,并从头开始学习编码来训练我们自己的神经网络。
让我们开始吧。
但首先,什么是反向传播?
MLPs 或多层感知器是完全连接的前馈深度神经网络,是我们今天看到的所有人工智能技术的核心。

它们由神经元组成。
神经元被堆叠成多层,一层中的每个神经元都连接到 MLPs 中下一层中的每个神经元。

在训练期间,输入数据通过这些神经网络,每一层都对其应用权重、偏差和激活函数,依次修改数据并在最后一层产生输出/预测。
此步骤称为前向传递或前向传播。

在此之后,将前向传递的输出预测与与输入数据关联的实际标签进行比较,并计算错误或损失函数。
这就是反向传播算法的用武之地,它计算相对于网络参数(权重和偏差)的损失的梯度,从最后一层向后迭代。
这是通过微积分中的链规则完成的,并告诉我们每个参数对错误的贡献(信用分配)。
此步骤称为向后传递。

反向传播后,优化器逐层更新/调整这些参数,以减少损失,从而产生更好的模型。
但是反向传播有什么问题呢?
尽管非常有效,但反向传播是内存密集型的。
还记得每个隐藏层在前向传递期间产生的所有输出吗?这些也称为中间激活,这些必须存储,因为它们都是稍后在后向传递中需要的。
对于具有数百层和数百万个神经元的神经网络,在训练期间存储中间激活可能会消耗多 GB 的 GPU VRAM。
(已经开发了像渐变检查点这样的技术来解决这个问题,但这仍然是一笔可观的费用。)
此外,由于反向传播是一种顺序算法,每个层的梯度计算取决于来自后续层的梯度。
这意味着我们不能通过跨层并行化来同时运行所有梯度计算,并且每个层必须等待它之后的层的梯度,然后才能继续自己的梯度计算。
反向传播训练的神经网络也分层学习事物,这意味着学习是跨多个抽象级别组织的,其中较低层学习简单的模式,较高层在此基础上学习更复杂的模式。
当梯度通过这些网络向后传播时,来自一个数据点或任务的更新可能会干扰来自其他数据点或任务的更新,导致网络有时完全忘记以前学习的数据(一种称为灾难性遗忘的现象)。
以下方法是以前作为反向传播替代品开发的许多方法中的一些,但没有取得太大成功。
这是因为它们在准确性、计算效率、可靠性或可扩展性方面较低。
- 零阶梯度法
- 直接搜索无梯度方法
- 基于模型的无梯度方法
- 自然进化策略
- 差分目标传播
- 前向-前向算法
那么有效的无反向传播学习还可能吗?
“NoProp” 来了
NoProp 算法借鉴了扩散模型(主要用于图像生成任务)的见解,并将其应用于图像分类(监督学习)任务。
如果你时间不够,想跳过数学细节,简而言之,这就是算法的工作原理。
在训练过程中,神经网络中的每一层/块都被赋予一个有噪声的标签和一个训练输入,它根据这些预测目标标签。
每一层都使用去噪损失独立于其他层进行训练。这消除了在训练期间前进通道的需要。
与训练不同,所有层在推理期间一起工作。
从高斯噪声开始,每一层都采用前一层产生的噪声标签并对其进行去噪。
这是逐层逐步完成的,网络从最后一层返回真正的类(完全去噪的表示)。
现在让我们详细探索这个算法的内部工作原理。
(如果您已经熟悉扩散模型,您将能够更好地理解这一点。)
给定来自数据集的样本输入 x 及其标签 y,我们的目标是构建一个模型,该模型可以预测给定输入 x 的标签 y。
从数学上讲,我们希望训练一个神经网络来建模一个随机过程,将随机噪声转换为允许我们估计 y 的形式,而不是找到一个函数 f(x) = y。
在这个过程中,理解两个分布很重要:
1. 随机正向/去噪过程
这个过程由 p 表示,如下所示:

它模拟我们如何从噪声开始,并通过一系列步骤将其降噪到最终表示 z(T),然后用于预测标签 y。
数学上,它是所有中间噪声表示 z(0), …, z(T) 和标签 y 的联合概率,给定 x。
在等式中:
p(z(0))描述标准高斯噪声p(z(t) ∣ z(t−1), x)描述了每一层如何对输入噪声进行去噪p(y ∣ z(T))描述了如何根据最终表示z(T)对y进行分类
p(z(t) ∣ z(t−1), x) 使用神经网络参数化,如下所示:

其中:
- 具有参数
θ的神经网络û,由a(t)加权,根据噪声输入z(t-1)和x预测去噪表示 b(t) ⋅ z(t−1)表示加权跳过连接√c(t) ⋅ ϵ(t)表示随机高斯噪声a(t),b(t),c(t)是用于称重等式的三个不同部分的定标器
2. 后向噪声过程/变分后验
这个过程由 q 表示,如下所示:

它模拟了我们如何从标签 y 开始(以其嵌入 u(y) 的形式)并逐步添加噪声,直到我们得到噪声 z(0)。
数学上,它是给定标签 y 并输入 x 的最终噪声表示 z(T) 的概率。
在等式中:
q(z(T) ∣ y)描述了给定标签y的表示z(T)xq(z(t−1) ∣ z(t))描述了通过添加更多噪声来达到更早噪声表示的反向扩散过程
q(z(T) ∣ y) 使用以下等式给出:

这意味着它是潜变量 z(T) 上的高斯分布,其中 √αˉ(T)⋅ u(y) 是平均值,1 — αˉ(T) 是方差。
u(y) 是标签嵌入,αˉ(T) 告诉在应用噪声过程后剩余多少 u(y)。
q(z(t−1) ∣ z(t)) 由以下等式给出:

这意味着它是潜变量 z(t-1) 上的高斯分布,其中 √α(t-1)⋅ z(t) 是平均值,1 — α(t-1) 是方差。
α(t−1) 是一个噪声调度参数,它控制在时间步长 t-1 保留多少原始信号。
请注意,术语 α 和 αˉ 来自固定余弦噪声时间表。
定义损失
NoProp 算法的训练目标是最大化正确标签的对数似然 log p(y∣x)。
但是直接优化这种对数似然在计算上是不可行的,因为它需要对所有可能的高维潜在变量 z(0), … , z(T) 进行积分。
作为一种解决方法,我们改为最大化它的变分下限,称为证据下限(ELBO)。


NoProp 损耗由以下表达式导出:

这看起来很复杂,但很容易理解。
在等式的右侧:
- 第一项是交叉熵损失,它测量最终表示
z(T)可用于预测正确标签y的准确性。 - 第二项是起始表示
z(0)分布和标准高斯噪声分布之间的 Kullback-Leibler(KL)散度,这种正则化鼓励这两个分布相似,这对于扩散过程正常工作是必要的。 - 第三项是逐层去噪损失,它通过比较其输出与真实标签嵌入的接近程度(由 L2 损失项给出)来衡量每一层去噪的程度。
在方程中,η 是超参数,术语 SNR 是信噪比,由以下方程给出:

当 t 增加时(当我们向后面的层移动时),信号增加(噪声减少),因此 SNR 增加。这使得整体去噪损失更大。
这意味着模型对来自较晚层(t 更接近 T)的错误的惩罚比早期层更多。
训练过程
在训练期间,网络学习对每一层的噪声标签嵌入进行去噪,而无需通过网络进行完整的前向或后向传递。
对于给定的输入标签对 (x, y),嵌入矩阵 W(embed) 将标签 y 映射到嵌入 u(y),该矩阵的每一行对应于标签 y 的嵌入 u(y)。
首先将噪声添加到 u(y) 以创建 z(t)。
然后,通过使用输入 x 预测干净的嵌入 u(y),独立训练每个神经网络层 û(θ)(z(t−1) , x) 以去噪先前的噪声表示 z(t-1)。
使用优化器计算训练损失,并更新网络参数,同时将此损失降至最低。
下面使用伪代码总结了训练算法。

推理过程
在推理期间,具有 T 总层/块的网络被赋予高斯噪声 z(0)。
每一层,从高斯噪声 z(0) 开始,依次从上一层获取输出 z(t-1),并输入 x,以产生下一个去噪表示 z(t)。
这导致在每个层处的噪声的中间形式的序列,由 z(0), z(1), …, z(t), z(T-1), z(T) 表示。
在最后一步 t = T,输出 z(T) 通过分类器来预测最终标签 ŷ。
z(0)连续地向 z(T)变换,每一层由 u(t)表示,以输入 x 为条件,最终产生预测标签 ŷ。

层/块架构
如上所述,每个层/块 û(θ)(z(t−1) , x) 本身就是一个复杂的神经网络,它需要:
- 输入
x并通过卷积嵌入模块对其进行处理,然后是全连接层 - 来自前一层
z(t-1)的噪声表示,并使用具有跳过连接的全连接网络对其进行处理
然后,这些输入通过额外的全连接层来生成 logits。
日志通过 softmax 函数,产生类嵌入的概率分布。
最终输出是通过使用此概率分布计算类嵌入的加权和来获得的。
每个层/块的架构,在上一张图片中显示为 u(t)

NoProp 的性能如何?
我们上面描述的是 NoProp 的离散时间(DT)变体,称为 NoProp-DT。
之所以这样称呼,是因为它被实现为在离散时间步长中对扩散过程进行建模,而不是连续的。
它还有另外两种变体,即:
- NoProp-CT(连续时间):此变体使用连续噪声计划并在连续时间跨度而不是离散步骤上对扩散过程进行建模。
- NoProp-FM(流匹配):此变体通过常微分方程(ODE)学习将噪声传输到预测标签嵌入的向量场,而不是去噪方法。
所有这些变体都与反向传播和以前的无反向传播方法在三个基准数据集上进行图像分类任务的比较:
- MNIST:包含 70,000 张手写数字灰度图像(每张 28 x 28 像素)的数据集,跨越 10 个类别(数字 0-9)
- CIFAR-10:包含 10 个不同对象类的 60,000 张彩色图像(每张 32 x 32 像素)的数据集
- CIFAR-100:包含 100 个不同对象类的 60,000 张彩色图像(每张 32 x 32 像素)的数据集
实验表明,NoProp 在所有三个数据集上实现了与反向传播和其他无反向传播方法相当或更好的性能。

不同训练方法对 MNIST 和 CIFAR 数据集的分类精度
除此之外,与其他方法相比,NoProp 在训练期间消耗的 GPU 内存更少。

从头开始编码无道具
现在我们知道了 NoProp 背后的理论,让我们自己学习编码并测试结果。
所有代码都是在 Jupyter 笔记本中使用 PyTorch 编写的,因此更易于跟踪和运行。
安装依赖项
如果您使用 Google Colab 笔记本运行此代码,则无需安装这些。
!pip install torch torchvision matplotlib
使用 GPU/Apple MPS(如果可用)
# Set device
if torch.backends.mps.is_available():
device = "mps"
elif torch.cuda.is_available():
device = "cuda"
else:
device = "cpu"
print("Using device:", device)
定义去噪块
这是去噪神经网络块(û(θ)),它接收以下内容:
- 一张图像
x - 一个有噪声的中间表示
z(t-1),以及 - 类嵌入矩阵
W_embed,其中包含标签嵌入u(y)作为其行
然后,它学习对有噪声的潜在向量 z(t-1) 进行去噪,并利用来自图像 x 的信息,使其更接近真实的标签嵌入 u(y)。
给定这些输入,它返回下一个表示 z(t)。
与传统的神经网络不同,这些块中的每一个都独立地学习去除标签嵌入的噪声。
# 去噪块
class DenoiseBlock(nn.Module):
def __init__(self, embedding_dim, num_classes):
super().__init__()
# 图像路径
self.conv_path = nn.Sequential(
nn.Conv2d(1, 32, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Dropout(0.2),
nn.Conv2d(32, 64, 3, padding=1),
nn.ReLU(),
nn.Dropout(0.2),
nn.Conv2d(64, 128, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Dropout(0.2),
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(128, 256),
nn.BatchNorm1d(256)
)
# 有噪声的嵌入路径
self.fc_z1 = nn.Linear(embedding_dim, 256)
self.bn_z1 = nn.BatchNorm1d(256)
self.fc_z2 = nn.Linear(256, 256)
self.bn_z2 = nn.BatchNorm1d(256)
self.fc_z3 = nn.Linear(256, 256)
self.bn_z3 = nn.BatchNorm1d(256)
# 组合的下游路径
self.fc_f1 = nn.Linear(256 + 256, 256)
self.bn_f1 = nn.BatchNorm1d(256)
self.fc_f2 = nn.Linear(256, 128)
self.bn_f2 = nn.BatchNorm1d(128)
self.fc_out = nn.Linear(128, num_classes)
def forward(self, x, z_prev, W_embed):
# 图像特征
x_feat = self.conv_path(x)
# 来自有噪声嵌入的特征
h1 = F.relu(self.bn_z1(self.fc_z1(z_prev)))
h2 = F.relu(self.bn_z2(self.fc_z2(h1)))
h3 = self.bn_z3(self.fc_z3(h2))
z_feat = h3 + h1 # 残差连接
# 组合并预测对数几率
h_f = torch.cat([x_feat, z_feat], dim=1)
h_f = F.relu(self.bn_f1(self.fc_f1(h_f)))
h_f = F.relu(self.bn_f2(self.fc_f2(h_f)))
logits = self.fc_out(h_f)
# 对对数几率应用Softmax
p = F.softmax(logits, dim=1)
z_next = p @ W_embed
return z_next, logits
定义 NoProp-DT 模型
这个模型通过 T 步扩散过程结合标签去噪,使用独立训练的 DenoiseBlock。
# NoProp-DT 模型
class NoPropDT(nn.Module):
def __init__(self, num_classes, embedding_dim, T, eta):
super().__init__()
self.num_classes = num_classes
self.embedding_dim = embedding_dim
self.T = T
self.eta = eta
# 堆叠去噪块
self.blocks = nn.ModuleList([
DenoiseBlock(embedding_dim, num_classes) for _ in range(T)
])
# 类嵌入矩阵(W_embed)
self.W_embed = nn.Parameter(torch.randn(num_classes, embedding_dim) * 0.1)
# 分类头
self.classifier = nn.Linear(embedding_dim, num_classes)
# 余弦噪声调度
t = torch.arange(1, T+1, dtype=torch.float32)
alpha_t = torch.cos(t / T * (math.pi/2))**2
alpha_bar = torch.cumprod(alpha_t, dim=0)
snr = alpha_bar / (1 - alpha_bar)
snr_prev = torch.cat([torch.tensor([0.], dtype=snr.dtype), snr[:-1]], dim=0)
snr_diff = snr - snr_prev
self.register_buffer('alpha_bar', alpha_bar)
self.register_buffer('snr_diff', snr_diff)
def forward_denoise(self, x, z_prev, t):
return self.blocks[t](x, z_prev, self.W_embed "t")[0]
def classify(self, z):
return self.classifier(z)
def inference(self, x):
B = x.size(0)
z = torch.randn(B, self.embedding_dim, device=x.device)
for t in range(self.T):
z = self.forward_denoise(x, z, t)
return self.classify(z)
定义训练函数
这个函数训练 NoProp-DT 模型(通过组合 T 个去噪块而不使用反向传播来创建)。
# 训练 NoProp-DT 的函数
def train_nopropdt(model, train_loader, test_loader, epochs, lr, weight_decay):
# 使用 AdamW 优化器
optimizer = torch.optim.AdamW(model.parameters(), lr=lr, weight_decay=weight_decay)
# 用于存储指标的字典
history = {'train_acc': [], 'val_acc': []}
for epoch in range(1, epochs + 1):
model.train()
for t in range(model.T):
for x, y in train_loader:
x, y = x.to(device), y.to(device)
uy = model.W_embed[y]
alpha_bar_t = model.alpha_bar[t]
noise = torch.randn_like(uy)
z_t = torch.sqrt(alpha_bar_t) * uy + torch.sqrt(1 - alpha_bar_t) * noise
z_pred, _ = model.blocks[t](x, z_t, model.W_embed "t")
loss_l2 = F.mse_loss(z_pred, uy)
loss = 0.5 * model.eta * model.snr_diff[t] * loss_l2
if t == model.T - 1:
logits = model.classifier(z_pred)
loss_ce = F.cross_entropy(logits, y)
loss_kl = 0.5 * uy.pow(2).sum(dim=1).mean()
loss = loss + loss_ce + loss_kl
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
# 训练准确率
model.eval()
correct, total = 0, 0
with torch.no_grad():
for x, y in train_loader:
x, y = x.to(device), y.to(device)
preds = model.inference(x).argmax(dim=1)
correct += (preds == y).sum().item()
total += y.size(0)
train_acc = correct / total
# 验证准确率
val_correct, val_total = 0, 0
with torch.no_grad():
for x, y in test_loader:
x, y = x.to(device), y.to(device)
preds = model.inference(x).argmax(dim=1)
val_correct += (preds == y).sum().item()
val_total += y.size(0)
val_acc = val_correct / val_total
# 存储准确率历史记录
history['train_acc'].append(train_acc)
history['val_acc'].append(val_acc)
print(f"Epoch {epoch}/{epochs} "
f"TrainAcc={100 * train_acc:.2f}% ValAcc={100 * val_acc:.2f}%")
# 绘制训练和验证准确率曲线
plt.figure()
plt.plot(range(1, epochs + 1), history['train_acc'], label='Train Accuracy')
plt.plot(range(1, epochs + 1), history['val_acc'], label='Validation Accuracy')
plt.title("Accuracy Curve")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.legend()
plt.grid(True)
plt.show()
print(f"\n Final Test Accuracy: {100 * val_acc:.2f}%")
定义超参数
作者在他们的实验中使用的超参数如下所示。

只有一个小的变化:我们只训练模型 10 个时期,而不是 100 个时期,因为这个训练量足以为我们的教程取得令人满意的结果。
# 超参数
T = 10
eta = 0.1
embedding_dim = 512
batch_size = 128
lr = 1e-3
epochs = 10
weight_decay = 1e-3
加载 MNIST 数据集
我们不会在 MNIST 数据集上应用数据增强技术。这与原始研究论文中的实验相似。
# 加载 MNIST
transform = transforms.ToTensor()
train_set = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_set = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transform)
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_set, batch_size=batch_size)
初始化模型
让我们使用我们定义的超参数来设置模型。
# 初始化模型
model = NoPropDT(num_classes=10, embedding_dim=embedding_dim, T=T, eta=eta).to(device)
训练模型
是时候开始训练了!
# 开始训练
train_nopropdt(model, train_loader, test_loader, epochs=epochs, lr=lr, weight_decay=weight_decay)
在训练结束时,我们获得了 98.88% 的验证准确率!
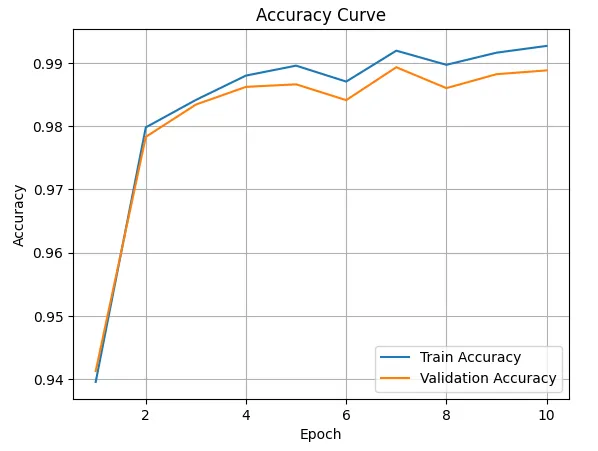
可视化预测
让我们绘制这些预测并可视化结果。
# 绘制预测的函数
def show_predictions(model, test_loader, class_names=None, num_images = 16):
model.eval()
images_shown = 0
plt.figure(figsize=(5, 5))
with torch.no_grad():
for x, y in test_loader:
x, y = x.to(device), y.to(device)
logits = model.inference(x)
preds = logits.argmax(dim=1)
for i in range(x.size(0)):
if images_shown >= num_images:
break
plt.subplot(int(num_images**0.5), int(num_images**0.5), images_shown + 1)
img = x[i].cpu().squeeze(0)
plt.imshow(img, cmap='gray')
actual = class_names[y[i]] if class_names else y[i].item()
pred = class_names[preds[i]] if class_names else preds[i].item()
plt.title(f"Pred: {pred}\nTrue: {actual}", fontsize=8)
plt.axis('off')
images_shown += 1
if images_shown >= num_images:
break
plt.tight_layout()
plt.show()
# MNIST 数据集的类名
class_names = [str(i) for i in range(10)]
# 可视化预测
show_predictions(model, test_loader)

推荐阅读
1. DeepSeek-R1的顿悟时刻是如何出现的? 背后的数学原理
2. 微调 DeepSeek LLM:使用监督微调(SFT)与 Hugging Face 数据
3. 使用 DeepSeek-R1 等推理模型将 RAG 转换为 RAT
4. DeepSeek R1:了解GRPO和多阶段训练
5. 深度探索:DeepSeek-R1 如何从零开始训练
6. DeepSeek 发布 Janus Pro 7B 多模态模型,免费又强大!
评论